

В 2025 году распознавание почерка перестало быть узкой задачей для айтишников и стало нормальным бизнес-инструментом. Современный ИИ уже не просто “видит буквы”, а понимает контекст, восстанавливает пропущенные куски и сразу выдаёт чистый текст, который можно загружать в CRM, BI и рекламные платформы.
Бумажные анкеты, брифы, опросы, регистрационные формы, заметки с мероприятий — всё это теперь автоматически превращается в структурированные цифровые данные. А гибрид OCR + LLM даёт точность 95–99%, что раньше казалось фантастикой.
Для бизнеса и руководителей это уже не «крутая фича», а фундамент для автоматизации рутины, повышения качества данных и запуска новых цифровых сервисов на базе AI.
Почему распознавание почерка так долго было проблемой?
Почерк — хаос. У всех разный стиль, наклон, размер букв, сокращения, пометки на полях. Иногда — смесь алфавитов. Для машин это настоящий визуальный джаз, в котором сложно выделить стабильные паттерны.

Классические OCR-системы умели работать только с аккуратным печатным текстом. Они видели пиксели, но не понимали смысл, поэтому “сыпались” на кривых строках, размытых сканах, слияниях букв и любом отклонении от идеальной формы.
Плюс, рукописные документы сами по себе часто очень разные: таблицы “уезжают”, строки пересекаются с рамками, структура нарушена. Это ещё сильнее усложняло автоматизацию.
В итоге обработка рукописных данных требовала много ручной правки, была дорогой и неточной. Но всё это было пока не появились более мощные AI-подходы.
Прорыв 2025: на сцену выходят LLM
Главным сдвигом в распознавании почерка в 2025 году стало подключение больших языковых моделей. В отличие от классических OCR, которые видят только символы, LLM понимают смысл текста и работают с ним как с полноценным сообщением.
Они угадывают, что автор хотел написать, исправляют ошибки, восстанавливают пропуски, держат контекст и “склеивают” разрозненные фрагменты даже в сложных, формах. Благодаря этому вместо сырых символов получается готовый, логичный текст, который можно сразу загружать в системы аналитики и автоматизации.
Когда LLM соединили с современными алгоритмами обработки изображений, точность распознавания выросла до рекордных значений — это стало настоящим технологическим прорывом.
Гибридный подход: OCR + LLM
Ключевое открытие 2025 года — связка OCR и LLM. Они отлично дополняют друг друга:
- OCR быстро вытаскивает символы с изображения, убирает шумы, распознаёт буквы и цифры. Но он не понимает смысла и не умеет исправлять логические ошибки.
- LLM берёт результат OCR, восстанавливает контекст, исправляет опечатки, «склеивает» обрывки и приводит текст к нормальной структуре. Более того, LLM может сразу перевести текст на другой язык!
По сути, OCR делает черновик, а LLM превращает его в готовый, читабельный и корректный текст.
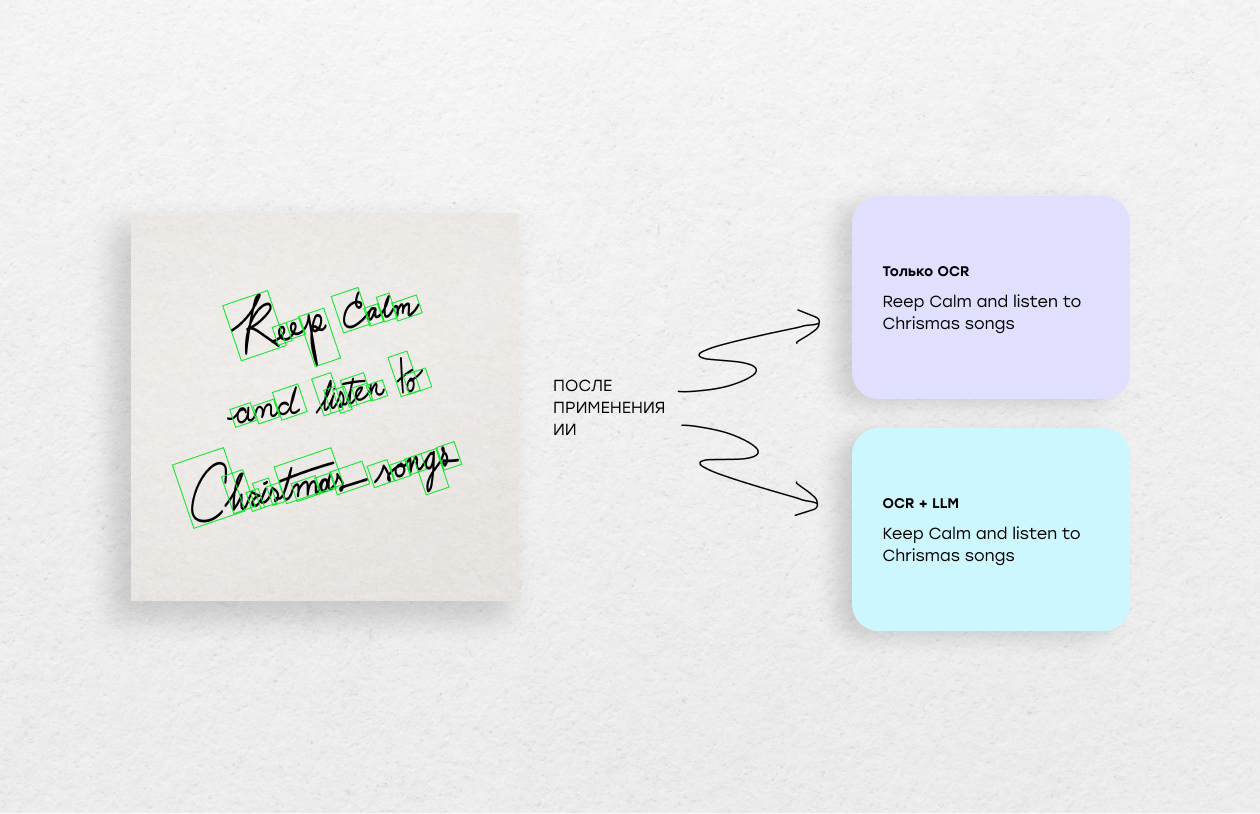
Такой гибрид резко сокращает количество ошибок и позволяет обрабатывать даже самые сложные рукописные формы — без ручной правки и за минимальное время.
Для бизнеса это означает быстрое и недорогое превращение любых рукописных документов — анкет, архивов, записок — в чистые цифровые данные, готовые к аналитике и автоматизации.
Наш мини-тест: как LLM справились с рукописным текстом

В рамках своего исследованияисследования мы протестировали три современных LLM — Gemini 2.5 Pro, GPT‑5 и Claude Sonnet 4.5 — на трёх реально «грязных» рукописных документах: форме регистрации, анкете и медицинском бланке.
Что получилось:
- Gemini 2.5 Pro стабильно лидировала: давала 98–99 % точности по символам, 99–100 % — по корректному извлечению полей, и почти идеальный JSON.
- GPT-5 оказался сильнее в семантике и «человечности» текста — он лучше понимал контекст и смысл, хотя иногда путал имена или структуру.
- Claude 4.5 давал менее чистый результат: чаще терялись пробелы, пунктуация, были ошибки в полях.

Что это значит для IT и бизнеса
Сегодня распознавание рукописного текста всё чаще становится частью платформ по интеллектуальной обработке документов, которые помогают компаниям автоматически захватывать, классифицировать и обрабатывать документы без ручного ввода.
Рукописные данные больше не надо вручную переносить в Excel. Анкеты, регистрации, заявки с офлайн-мероприятий — всё автоматически превращается в аккуратные цифровые записи. Команды быстрее собирают первичные данные и запускают аналитику без задержек.
Для IT‑рынка распознавание рукописного текста — это не просто внутренняя автоматизация, а платформа для целого класса новых продуктов: от облачных IDP‑сервисов до вертикальных SaaS‑решений для финтеха, медицины, логистики, госуслуг и образования.
Для бизнеса это означает появление новых цифровых точек контакта и бизнес‑моделей: рукописные формы, заметки, акты, медицинские карты или чековые книжки превращаются в машиночитаемые данные, которые можно сразу отдавать в CRM, риск‑модели, аналитические витрины или клиентские сервисы.
На этом уровне рукописный ввод перестаёт быть «аномалией офлайна» и становится таким же полноправным каналом данных, как веб, мобильные приложения или сенсоры, а компании, которые научились его монетизировать, получают конкурентное преимущество на быстрорастущем рынке IDP и AI‑продуктов.
Для бизнеса в целом это возможность высвободить время специалистов для более сложных задач, ускорить вывод продуктов на рынок и масштабироваться без прямой привязки к росту штата. Настоящий must-have 2025 года.
Заключение
Распознавание рукописного текста уже стало частью глобального тренда на интеллектуальную обработку документов: рынок IDP оценивается в несколько миллиардов долларов и растёт двузначными темпами ежегодно. Распознавание почерка стало не техническим трюком, а полноценным инструментом повышения эффективности и конкурентоспособности брендов.
Компании, которые начинают экспериментировать с такими решениями сейчас, получают конкурентное преимущество — им проще автоматизировать процессы, снижать долю ручного труда и точнее понимать, что происходит в их данных.
Поэтому рукописный текст стоит воспринимать не как "вечную проблему неразборчивого почерка", а как ещё одну точку входа в экосистему AI‑инструментов, которая меняет то, как устроены IT‑ландшафты и современный бизнес в целом.
Полезно увидеть детали, которые обычно остаются за кадром.
Интересный кейс, особенно понравилось, что объяснили без лишней воды.
Не со всем согласен, но аргументы сильные. Было бы интересно увидеть продолжение.
Люблю такие разборы: без громких обещаний, зато с понятной логикой.