

Команда разработки Аспро.Cloud росла, задач становилось больше, но организованности не хватало. Спринты расходились по срокам, релизы сдвигались, бэклог раздувался. Мы пересобрали процессы и навели порядок без жестких реформ. В кейсе рассказываем, какие управленческие практики помогли вернуть команде ритм и повысить эффективность.

Когда продукт развивается и команд становится больше, привычные процессы перестают справляться с нагрузкой. В разработке Аспро.Cloud шесть команд работали по Scrum, но фактически каждая жила в собственном ритме.
Спринты начинались в разные дни, длились по-разному, релизы переносились. Бэклог рос, задачи зависали на этапах, а сроки становились менее предсказуемыми. Мы поняли, что проблема не в людях и не в нагрузке — сбой произошел на уровне управления процессами.
Мы не стали кардинально менять методологию. Вместо этого пересобрали рабочую систему: синхронизировали команды, расширили рабочий процесс, усилили подготовку задач и ввели строгую приоритизацию.
Единый ритм вместо разрозненных спринтов
Первое, что создавало хаос, — отсутствие общего цикла работы. У одних команд спринт начинался в понедельник, у других — в среду. Где-то он длился неделю, где-то две, а иногда растягивался почти на месяц. Дедлайны сдвигались, задачи переносились, релизы не фиксировались как отдельный результат.
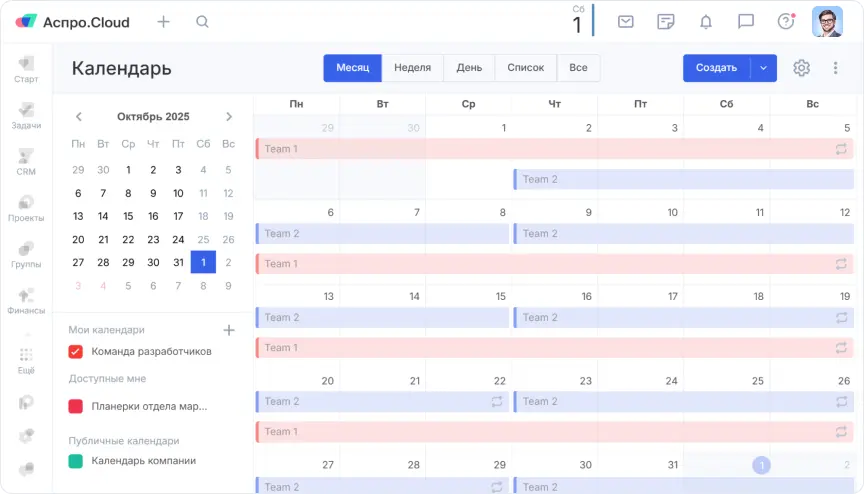
Мы ввели единый двухнедельный спринт для всех команд с четкими датами старта и завершения.
Теперь:
- первый понедельник — начало спринта
- третий понедельник — релиз и ретроспектива
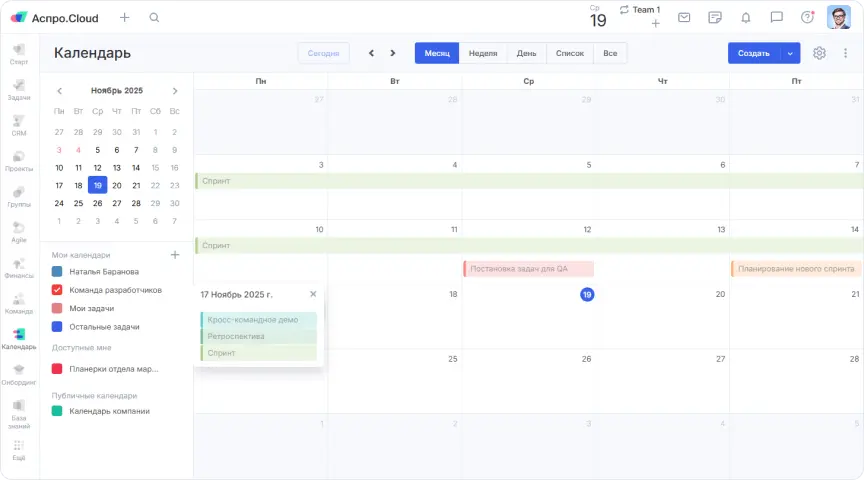
Дополнительно закрепили промежуточные дедлайны для передачи задач в тестирование. Это позволило заранее понимать, что попадет в релиз, а что переносится.
Отдельно запустили кросскомандное демо. На него приглашаем маркетинг, поддержку, руководителей и собственников. Каждая команда показывает результат за две недели. Это усилило прозрачность и сняло постоянные вопросы о сроках.
Расширенный жизненный цикл задач
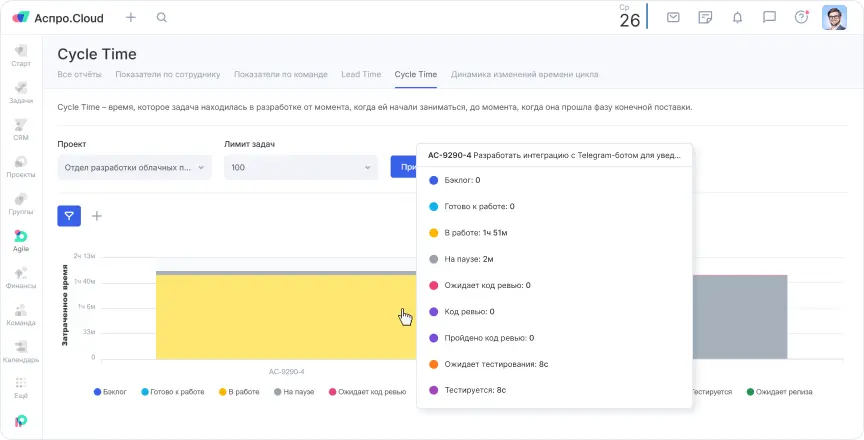
Следующая проблема скрывалась в самой Scrum-доске. Раньше этапы были стандартными: сделать, в работе, код ревью, тестируется, выпущено. Но доска не показывала реальное состояние задачи. Если карточка стояла в колонке «Код ревью», было непонятно — ее уже проверяют или она просто ждет очереди.
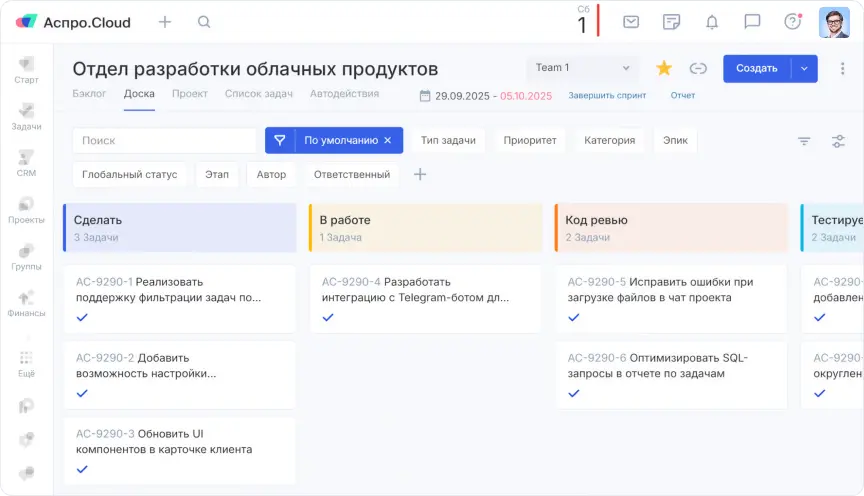
А если возникал блокер, задачу возвращали в «Сделать», и она визуально выглядела как новая. История терялась.
Мы расширили рабочий процесс и добавили промежуточные этапы:
- бэклог
- готова к работе
- ожидает код ревью
- пройдено код ревью
- ожидает тестирование
- ожидает релиза
- на паузе
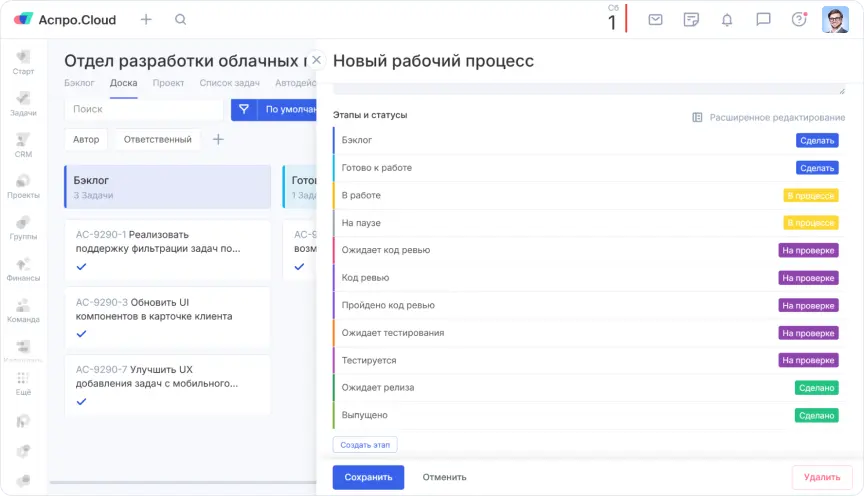
Разделение позволило видеть, где именно задача застряла. Появилась возможность анализировать узкие места: например, если карточки долго стоят на этапе ожидания тестирования, это сигнал к перераспределению ресурсов.
Definition of Ready как фильтр качества
Одна из ключевых причин переделок — слабая подготовка задач. Формулировки вроде «Сделайте, чтобы было удобно» приводили к бесконечным уточнениям и возвратам.
Мы внедрили Definition of Ready — критерии, которым должна соответствовать задача перед тем, как попасть в работу.
Базовые принципы:
- Четкое описание. Используем подход Jobs to Be Done. Вместо «Добавить кнопку экспорта» формулируем контекст и цель пользователя. Это помогает команде понимать ценность, а не просто выполнять действие.
- Понятная бизнес-ценность. Каждая задача должна отвечать на вопрос, зачем она продукту и пользователю.
- Достаточность ресурсов. Если не хватает компетенций или информации, задача уходит в исследование, а не блокирует спринт.
- Реализация за один спринт. Крупные задачи декомпозируем. Это повысило предсказуемость планирования.
После внедрения сократилось количество возвратов и упростилось планирование.

Автоматизация межкомандной коммуникации
Разработчики активно взаимодействуют с тестировщиками, маркетингом и поддержкой. Раньше многие договоренности оставались устными или фиксировались в чатах. Это отвлекало и создавало лишние напоминания.
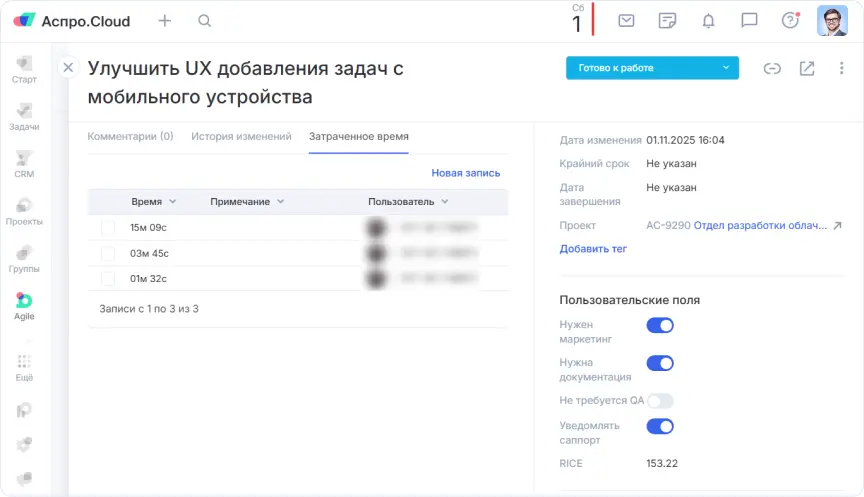
Мы добавили пользовательские поля-триггеры в задачах. Например, при включении поля «Нужен маркетинг» маркетологи получают автоматическое уведомление. Это не исключило общение полностью, но избавило от рутинных напоминаний и ручных сообщений.
Переход к квартальному планированию
Мы заметили, что живем от спринта к спринту. Краткосрочные задачи вытесняли стратегические инициативы.
Чтобы вернуть фокус, внедрили квартальное планирование. Теперь:
- согласовываем цели со стейкхолдерами
- фиксируем ключевые инициативы
- проводим квартальные ретроспективы
- балансируем операционные и долгосрочные задачи
Это помогло связать ежедневную работу с продуктовой стратегией.
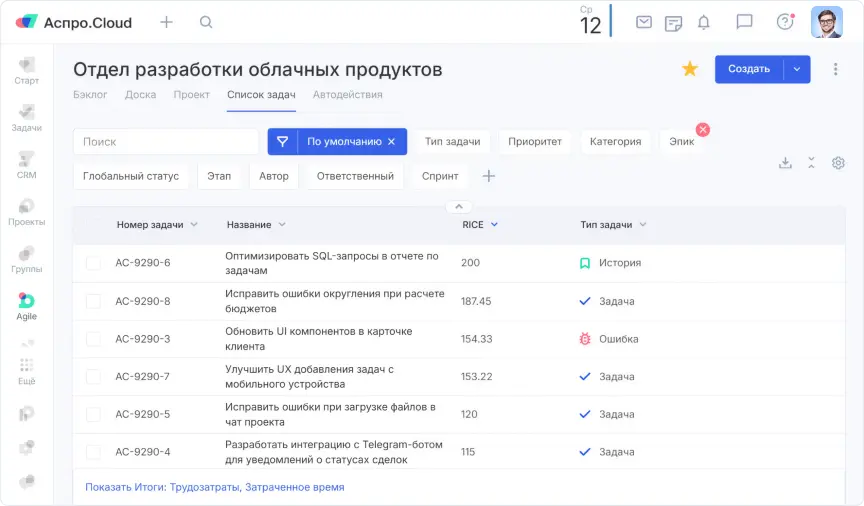
Приоритизация бэклога
Со временем бэклог вырос до 2000 задач. Приоритеты «высокий, средний, низкий» перестали работать: десятки задач имели одинаковый статус.

Мы внедрили приоритизацию по RICE:
- reach — охват
- impact — влияние
- confidence — уверенность
- effort — трудозатраты
Такой подход дал числовую оценку задач и упростил планирование спринтов. Мы перестали ориентироваться на субъективные ощущения и перешли к системной оценке влияния.
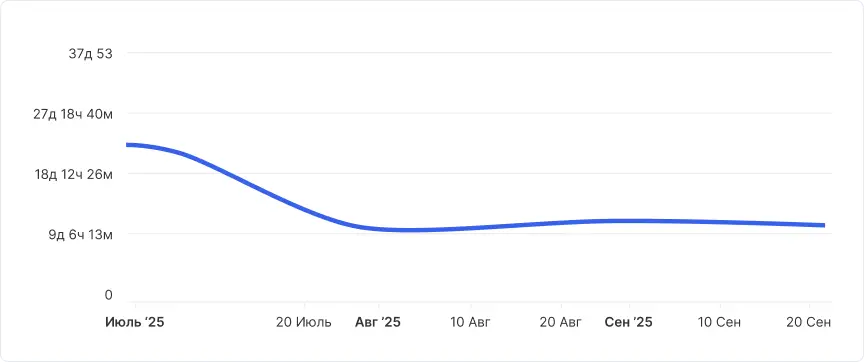
Что изменилось в цифрах
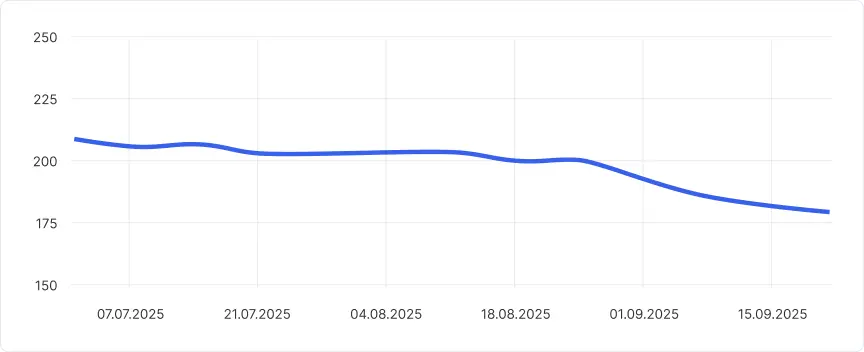
- Главной целью было сокращение Time-to-market — времени от статуса «Готова к работе» до «Выпущено».
- Мы снизили этот показатель почти в два раза — с 23 до 11 дней. Тренд остается нисходящим.
- Также удалось снизить медианный возраст задачи в бэклоге с 7 до 6 месяцев.
- Команда стала быстрее принимать решения, релизы стали регулярными, а процессы — прозрачными для всех участников.

Интересный кейс, особенно понравилось, что объяснили без лишней воды.
Хорошо разложено по шагам, стало понятнее, где обычно теряется время.